FlowRadar VPN Detection Challenge
Overview
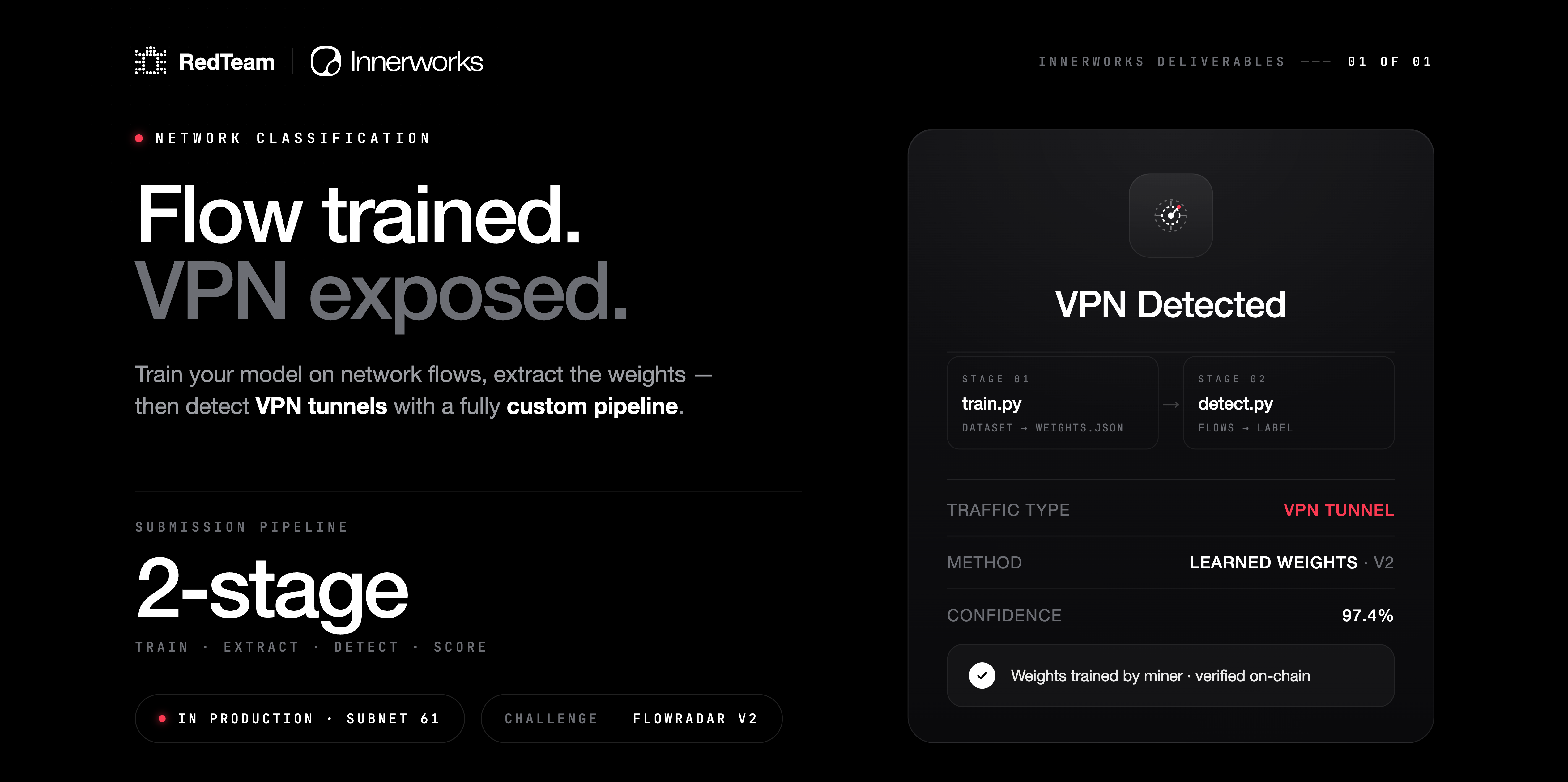
FlowRadar is a network-flow classification challenge for detecting VPN traffic. FlowRadar v2 introduces a two-stage miner pipeline:
- Train a model from the mandatory production training dataset.
- Use the generated model to classify production test flows.
Miners submit two Python files through miner_output.commit_files:
train.pysubmissions.py
The challenge runs both files inside an isolated FlowRadar container. Miner Python is never executed by the main challenge API process.
Production Data
- Training:
v2_train_data.csv - 100,000 rows
- 110 columns
- label:
vpn_is_enabled - Scoring:
v2_test_data.csv - 400,000 rows
- same v2 schema
The production training dataset is mandatory. Miners cannot replace it or select another training file.
Submission Shape
{
"miner_output": {
"commit_files": [
{"file_name": "train.py", "content": "..."},
{"file_name": "submissions.py", "content": "..."}
]
}
}
Exactly these two files are required. Duplicate names, additional files, path-based names, and empty content are rejected.
Embedding pretrained or externally generated learned weights in either file is
prohibited. Every model must be trained from v2_train_data.csv during the
current scoring run.
Challenge Flow
- The challenge receives
train.pyandsubmissions.py. - It starts an isolated FlowRadar container.
- Both files and
v2_train_data.csvare mounted read-only. - The challenge calls the container's
POST /trainendpoint. train.pywrites a temporary JSON model.- The challenge replays
v2_test_data.csvthrough/vpn_detector. submissions.pyreturns one boolean prediction per flow.- The final score is calculated using F1.
Challenge Versions
Resources
References
- RedTeam Subnet: https://www.theredteam.io
- FlowRadar repository: https://github.com/RedTeamSubnet/flowradar-challenge
- Docker: https://docs.docker.com